Multi-cloud is now the operating reality of every serious enterprise. Governing it requires four disciplines – not another tool. A field-tested framework for the CIOs running it.

Tata Communications
Walk into almost any large enterprise today and ask the CIO how their multi-cloud is going. The answer is rarely a single sentence. It’s a list of qualifications: two strategic hyperscalers, a third for a regulated workload, a sovereign cloud for one geography, a colocation footprint for latency-sensitive systems, an on-premises estate that hasn’t gone anywhere, and a long tail of SaaS that quietly behaves like infrastructure when it fails.
This is not a failure of strategy. It is the strategy. Multi-cloud is the operating reality of every serious enterprise, driven by acquisition history, regulatory geography, AI workload economics, and the simple fact that no single provider is best at everything. The question has shifted from whether to run multi-cloud to how to govern what we already have.
And on that question, most enterprises are still trying to buy their way out. Another observability tool. Another policy engine. Another connectivity overlay. The result, predictably, is a stack with more dashboards than the people watching them have hours in the day, and a complexity tax that compounds in the seams between every tool the procurement team has signed off on.
The CIOs I work with – increasingly – have stopped asking what to buy next. They’ve started asking a different question: what would it take to run multi-cloud the way we already run finance, or security, or supply chain? As an operating discipline. Not a project. Not a stack. A continuous loop, with clear ownership and a clear cycle.
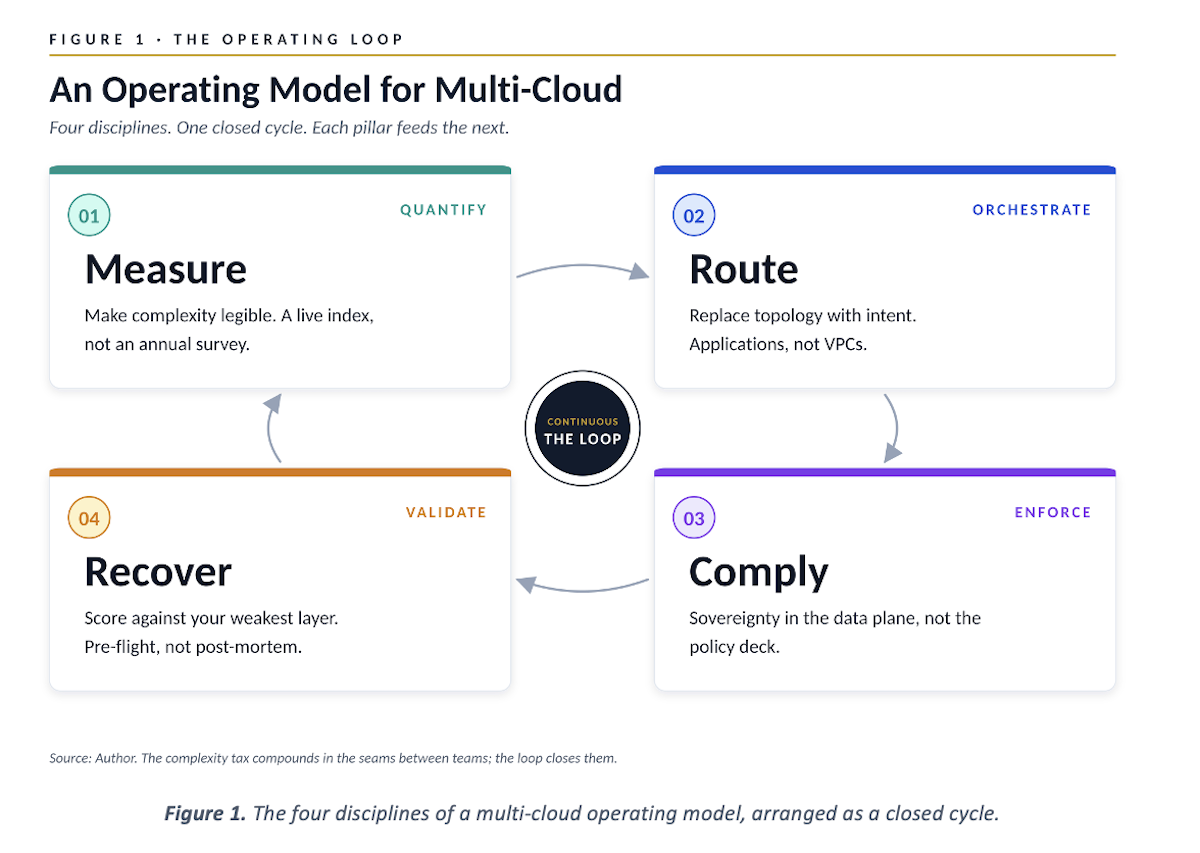
That is the case I want to make. Multi-cloud has matured past the point where it can be governed by tools alone. It needs an operating model with four disciplines, each of which the next three years will judge every CIO on: Measure, Route, Comply, Recover (Figure 1).
These aren’t sequential phases. They’re a closed loop. And the platforms that close it – disclosure: my team at Tata Communications is building one called IZO+ Multi Cloud Network (MCN) – are about to redefine what good multi-cloud looks like. The platforms that don’t will, eventually, be remembered as dashboards bolted onto point tools.
Tata Communications
Figure 1. The four disciplines of a multi-cloud operating model, arranged as a closed cycle.
PILLAR 1
Measure: Quantify what your bill never will
Of all the line items on the enterprise technology balance sheet, the largest one is the one no system reports: the cost of complexity itself. CFOs receive a cloud bill every month. CIOs receive an uptime dashboard every morning. Neither captures the cost of the routine policy change that needs three tickets across two teams, or the configuration drift in one region that surfaces as a customer outage in another, or the senior-engineer time spent reconciling things that should never have diverged.
The first discipline of a multi-cloud operating model is to make this cost legible. That means a complexity index – a quantified score, not a qualitative survey – that decomposes into the dimensions actually driving it: base connectivity, cross-domain coupling, governance gap, toolchain fragmentation, and geographic dispersion. (My team has built and patented one called the Enterprise Multi-Cloud Complexity Index. The framework matters more than the brand.)
A good index does three things a one-off assessment cannot: it is continuous (the score moves with reality, not with the audit cycle), decomposable (it tells you which dimension is driving the number, so remediation can be prioritised), and peer-benchmarked (it tells you whether your number is normal for your industry and your scale).
The CIO insight is simple: a one-off complexity score is a slide. A live one is an operating signal. And once you have an operating signal, you can do something with it. That something is the next three disciplines.
PILLAR 2
Route: Make applications self-networking
Once you can see complexity, the next discipline is to stop accumulating more of it. That is what routing – done right – does.
The traditional multi-cloud network is defined by infrastructure topology: VPCs, VLANs, transit gateways, peering connections, the long tail of NATs and firewalls in between. Every new application inherits that topology. Every new region multiplies it. Every team learns it differently. The result is what most enterprises now have: a network that can technically reach everywhere but can’t be reasoned about anywhere.
The shift that matters is from infrastructure-defined to intent-defined routing. The right unit of design is no longer the VPC; it is the application – or, more precisely, an Application Connectivity Domain (ACD): a logical boundary that spans clouds, regions, and on-premises footprints, and within which an application’s reachability, identity, and policy travel together. The infrastructure underneath becomes a substrate to be orchestrated, not a topology to be hand-stitched.
For AI workloads in particular, this matters more than most CIOs realise. All-reduce performance, inference latency, and data-gravity economics are all functions of physical fabric layout – GPU placement, interconnect topology, regional data residency. A network that doesn’t know where the GPUs are will route AI traffic the way it routes everything else, and the training run will pay for it.
The CIO question to ask: can my network be defined by what my applications need, or only by where my infrastructure happens to sit?
PILLAR 3
Comply: Move sovereignty into the data plane
For most enterprises, compliance is still something that happens after a routing decision is made. A packet flows; an audit later confirms whether it should have done so. A workload runs in a region; a quarterly review checks whether the data residency clause was honoured.
That model has expired. Between GDPR Article 44, India’s DPDP Act, the EU AI Act, the patchwork of GCC sovereignty mandates, and a growing list of sectoral regulations, jurisdictional rules now change faster than annual audits can catch up with them. Treating sovereignty as an after-the-fact check guarantees one of two outcomes: a compliance violation, or a chilling effect that slows every cloud decision into paralysis.
The discipline I’d urge every CIO to adopt is pre-flight compliance: jurisdictional assurance built into the routing decision itself, not bolted on afterwards. Before a workload is placed, before a packet leaves a region, before a failover target is chosen, the platform should already know which jurisdictions are eligible – and silently exclude the ones that aren’t. Compliance becomes a property of the data plane, not a clause in a policy deck.
The shift in CIO conversation is unmistakable when this works. The board no longer asks “Are we compliant?” They ask “What would it cost to add another jurisdiction?” – and the answer is a configuration change, not a programme.
PILLAR 4
Recover: Score yourself against your weakest layer
The February 2026 AWS UAE infrastructure incident was, for many of the CIOs I work with, the moment the recover discipline stopped being theoretical. Enterprises that had spent years building “multi-region” architectures discovered that being multi-region and being recoverable are not the same thing. Their compute had a backup region. Their data didn’t. Or their data did, but their identity layer was tied to the failed region’s IAM. Or every layer was technically replicated, but no one had ever tested the failover end-to-end under load.
The most useful framing I’ve seen is the Failover Readiness Score (FRS): a single number scored as the weakest of five layers – Infrastructure-as-Code, Network, Data, Workload, and Sovereignty. The weakest-link formulation is the entire point. Your real recovery time objective is governed by your worst-prepared layer, not your average. An IaC pipeline that can spin up a region in ninety seconds means nothing if the database promotion takes four hours, or if the failover target turns out to be sovereignty-ineligible for the data you’re moving to it.
Pre-flight failover simulation – running the failover continuously in shadow mode against multiple targets and reporting which are viable – is the discipline that separates resilience theatre from actual recoverability. The CIO question: if I had to fail over right now, against my second-best target, would my weakest layer let me?
THE SYNTHESIS
The loop
The four disciplines look like a stack. They are actually a feedback cycle.
Measure identifies the highest-complexity surfaces in your estate. Route lets you bypass or absorb them without rebuilding applications. Comply ensures every routing and failover decision is jurisdictionally clean by construction. Recover validates, continuously, that your weakest layer can carry the load when something goes down – and feeds the result back to Measure, which updates the complexity score and the cycle starts again.
The reason the loop matters more than any single pillar is that it eliminates the place where complexity wins today: the seam between teams. Today, measurement lives with the FinOps and architecture teams; routing lives with networking; compliance lives with risk; recovery lives with SRE. Each owns its piece. Nobody owns the seam. The complexity tax compounds in the seam.
A platform that closes the loop collapses the seams. That is the structural change underway in our category, and it is the change CIOs should be evaluating vendors against.
A four-question test for your next vendor conversation
Before the next multi-cloud purchase, ask:
- Can I measure complexity continuously, not just survey it? A score that doesn’t move with reality is a slide, not a signal.
- Can I route around complexity without rebuilding applications? If every new connectivity decision means new infrastructure, you’ve bought a tool, not a fabric.
- Is compliance enforced in the data plane, or only in policy decks? If the answer involves a quarterly review, your sovereignty posture is a hope, not a guarantee.
- Is my failover readiness scored against my weakest layer? Average preparedness is the wrong number. The weakest-link score is the only honest one.
If your current stack can’t answer all four with a straight yes, the right next move isn’t another point tool. It’s the loop. That, more than any individual product capability, is what separates the CIOs who will spend the next three years firefighting multi-cloud from the ones who will spend it compounding it.
To learn more, visit us here.
————————————————————
>About the author. The author leads product and strategy for IZO+ MCN, a multi-cloud overlay networking platform developed by Tata Communications. The Enterprise Multi-Cloud Complexity Index (EMCI) referenced in this article is a patent-pending framework. Views are the author’s own.